
2021年8月15日,清华大学人工智能国际治理研究院副院长梁正教授出席《未来论坛 AI伦理与治理系列第4期——AI决策的可靠性和可解释性》。本次论坛旨在从不同的角度阐明公众、政策法规和AI技术从业者对AI可靠性的理解和需求,分享AI的可解释性、稳定性和鲁棒性、可回溯可验证等方面的技术研究和解决方案,共同探讨实现可解释和可靠AI的可行路径。梁正教授在论坛上发表了题为《从可解释AI到可理解AI:基于算法治理的视角》的报告。

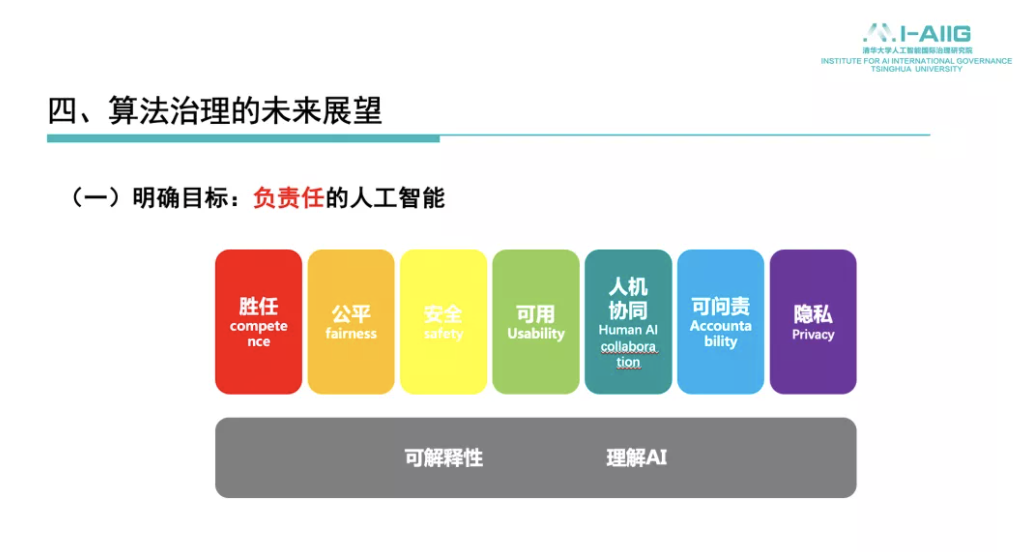
梁正教授指出可靠的AI应该具备四大要素:安全、公平、透明、隐私保护。因此,“可信任”和“可解释”是正向相关关系,尤其对用户和公众而言,实现算法可解释是确保可靠和信任的重要一环。其次,“负责任的人工智能”有两个基石,即从技术角度去解决其因果机制的构建问题和从制度角度赋予个人和主体可解释的权利。此外,他还指出,和欧美国家相比,我国算法治理相关的规则目前比较分散,缺乏实施的细则和操作指引;在算法治理上,统一协调负责的监管机构还不明确。而未来算法治理要发展的两大方向也已比较明确,即可问责性和可解释性。现将梁正教授主题报告的主要内容推出,以飨读者。
在本次主题报告中,梁正教授从四个方面探讨了人工智能治理,对“可解释性AI”的理解与认识,“可信任”和“可解释”之间的关系,为什么我们需要关注可解释性问题,关于这一问题的当前实践和经验又有哪些,我国是如何探索算法治理路径的,以及未来我们可以如何设计算法治理路径。

一、为什么关注AI可解释性问题
为什么要关注AI或者算法的可解释性?
今天机器学习的主流呈现出“黑箱”的特点,普通用户很难观察到数据训练的中间过程,这样的特征导致AI对我们而言处在不可知的状态。黑箱问题也带来了难以控制、歧视偏见和可能存在的安全风险,使得我们对算法信任产生怀疑。一些重要的应用领域尤其如此,比如医疗健康、金融、司法领域,包括自主决策的AI系统,算法可解释性是非常重要的应用依据,特别是在金融领域,一些监管机构也提出可解释性是应用的先决条件。

什么是算法的“可解释性”?
学界从不同的角度来认识,国外学者以及部分国内学者认为“可解释性”是可以提供细节和决策的依据,能够被用户简单清晰的认识和理解。从法律法规角度来看,欧盟《通用数据保护条例》(以下简称“GDPR”)规定在自动化决策中用户有权获得决策解释,处理者应告知数据处理的逻辑、重要性,特别是影响后果,这是学理层面、政策层面上的“AI可解释性”。

“可解释”和“可信任”之间是什么关系?
普通用户对“可解释”的认知更多的是可理解,即不需要掌握更多专业知识但可以简单清晰地理解自动化决策的原因和根据,这涉及与“可理解”含义的关系。从用户角度来说,AI应该是可靠的,即不能出错、不能产生风险、不能损害我们的利益或者安全。由此,可靠的AI应该具备四大要素:安全、公平、透明、隐私保护。因此,“可信任”和“可解释”之间是正向相关关系,尤其对用户和公众而言,实现算法可解释是确保其可靠和信任的重要一环。
算法可能带来的风险有哪些?
即不可靠的因素或者风险因素何在——比如歧视和偏见问题,由于技术本身的局限可能现阶段带来的可能的安全问题,因与社会系统嵌合而产生的数字劳工劳动受限的问题,还有信息推荐领域基于用户偏好的信息投递而可能存在的“信息茧房”问题等。它们和我们所使用的数据和算法相关,也与AI及深度学习本身的特点相关。
二、对于算法治理,目前国内外已有实践和经验
各国在算法治理方面有不同的探索,也有共性和经验。

欧盟的数据治理和算法治理
欧盟在数据治理和算法治理方面的特点是自上而下,规则制定色彩比较浓厚,也提出特别明确的原则——以“透明性”和“问责性”保证算法公平。“透明性”就是指AI可解释性,即决策数据集、过程和决策可追溯性,决策结果可以被人类(包括监管部门、社会公众)理解、追踪。“问责性”则规定如何保证AI是负责任的、安全的,要建立问责机制、审计机制以及风险损失的补救措施。具体治理路径是把数据权利赋予个人,在GDPR中规定了知情权、访问更正权、删除权、解释权,赋予个体广泛的数据权利。从欧盟近期出台的《数字服务法》、《数字市场法》等一系列法律法规来看,其未来的发展方向更倾向于强化法律责任制度,设定严格的责任,通过事后严格追责来保证在AI的设计和应用上是负责任的、可信的。比如强制保险制度,法律上对AI损害的侵权判定不需要了解其技术细节,只需要认定侵害行为和损害之间的因果关系即可构成侵权。举例而言,近期意大利数据保护机构对一家外卖快递公司处以罚款,原因在于该平台通过算法自动处罚骑手,如果骑手的评分低于某个水平,就可以停止其工作。监管机构认为该处罚原则是一种歧视,因为骑手没有能力争辩,也不了解这样的评判是基于何种标准。所以,公司对于这样的算法应用应该做出解释,员工应该有知情权。

美国的数据治理和算法治理
与欧盟不同,美国采用了另一条路径,其联邦层面并没有统一制定算法治理的相关法律,而是采取自下而上的、分散化、市场化的治理路径。比如,纽约市最早出台算法问责法,对于政府使用的算法(比如教育领域、公共部门)进行监管与问责,麻省、加州、纽约市等多个州和城市禁止政府和司法部门使用面部识别技术;此外,加州制定的《加州消费者隐私保护法案》(CCPA),赋予公民查询、了解其个人数据收集和使用情况的权利,该治理路径与欧盟GDPR更加接近;在私人主体方面,更多是企业和非政府组织的参与治理,以及部分行业组织进行算法问责工具、算法可解释方案的开发。就行业自律而言,谷歌、微软、Facebook等企业成立了伦理委员会,并推动建立相关标准。相关案例有很多,比如近期Everalbum公司在隐私条款中没有写明的情况下,将算法卖给执法机关和军方,涉嫌欺骗消费者,最终被美国联邦贸易委员会(FTC)处罚。这是一个具有标志性意义的处罚判定,不仅仅要求其删除数据,还要求删除非法取得的数据照片所训练出的人脸识别技术。
三、我国对算法治理的路径探索
现阶段我国对算法治理路径的探索,已经初步形成了框架体系
在“软法”也即规范原则方面,科技部发布了《人工智能治理原则》,全国信息安全标准化技术委员会(信安标委)发布了《人工智能伦理安全风险防范指引》,以及最近多个部门在相关领域所出台的针对平台企业或者针对某个特殊领域的数据管理、算法治理相关的规章制度。
与此同时,多部“硬法”也正在密集地研究制定和实施当中,比如已经实施的《电子商务法》《网络安全法》,即将实施的《数据安全法》和即将通过的《个人信息保护法》等多个部门规章。目前的问题在于,较之于欧美,我国现有的监管规则比较分散,缺乏实施的细则和操作指引;在算法治理上,统一协调负责的监管机构还不明确。中央网信办在某种程度上起到牵头协调作用,但在具体领域相关的职能部门要发挥更多作用。
在产业界,部分企业开始建立内部治理机制,比如治理委员会,对数据的采集、利用,以及算法设计等问题进行规制,但整个行业自治机制尚不成熟,同时也缺乏外部监督。
未来算法治理方向
基于人工智能算法可能存在的风险,并进一步借鉴国外的已有经验,未来算法治理的两大方向比较明确:一是算法可问责,主要是明确算法责任主体,对于监管部门而言,不是做技术规制而是做责任的划分,即一旦出现问题,谁应该承担责任,包括算法审计制度,也即对算法应用的监督、安全认证制度,也即算法设计要遵循一定的标准、规范、制度、规则,以及算法影响的评估制度。二是可解释性,技术上如何实现可解释,以及制度上如何赋予个人要求解释的权利,进而反作用于算法的设计以达到公平合理的目标。

在自动化决策场景中的治理尝试
目前的实践性探索集中在《个人信息保护法》层面,主要为自动化决策场景中算法治理的尝试,包括明确提出对算法影响的评估,规定利用个人信息进行自动化决策需进行事前评估、算法审计;特别是赋予个体权利,保障自动化决策透明度和结果的公平合理,对个人权益有重大影响的领域(比如金融、医疗等)个人有权要求信息处理者予以说明,并有权拒绝仅通过自动化决策的方式作出决定。
在自动化决策场景下的治理探索方面,央行在人工智能算法金融应用领域设立了评价规范,提出对算法可解释性要从全过程的角度提出基本要求、评价方法与判定标准等。人社部在关于就业形态灵活化与劳动者权益保障方面,提出外卖平台在基本的业务模型设计上,应该对其制度规则和平台算法予以解释,并将结果公示或告知劳动者。中宣部在关于加强网络推荐算法的内容监管方面,也提出综合治理的要求。所以,未来的算法治理基于可解释性、基于可靠性的方向较为明确,所谓“负责任的人工智能”,它有两个基石:一是从技术角度去解决其因果机制的构建问题,二是从制度角度赋予个人和主体可解释的权利。
四、未来对于算法治理路径的设计和方向展望
未来的算法治理基于可解释性、基于可靠性的方向较为明确,所谓“负责任的人工智能”,它有两个基石:一是从技术角度去解决其因果机制的构建问题,二是从制度角度赋予个人和主体可解释的权利。
就未来可能的治理方向而言,对于算法未来的目标是分领域、分级的治理,比如人身安全领域和商业领域可能要进行分类处理。在坚持安全、公平、透明和保护隐私的基本原则上实现“负责任的AI”。算法的“黑箱”特征和复杂性不能成为逃避治理的借口,应该在保护人们基本权利的基础上设定底线,在算法性能和安全之间进行权衡,推动技术界去改良算法。此外,应当在算法治理中识别和区分规则问题和技术问题,认识到算法设计不单单是机器学习的结果,还需要对算法设计人进行约束,找到问责主体。而对于技术缺陷,则应该通过技术进步,以及相应的标准规范与安全要求去引导技术开发。最后,应该提出算法可解释的评估指标和监管政策,研究提出全流程的监管政策,定期评估AI系统的生命周期和运转状态。有专家对于AI可解释性的具体方式存在争议——是公开模型、源代码、运算规则,还是决策的权重因素,这是否会影响到企业的商业秘密等,这些都是亟待下一步研究明确的问题。
感谢未来论坛协助整理
